IA en auditorías de Web Performance: medición determinística e informes accionables
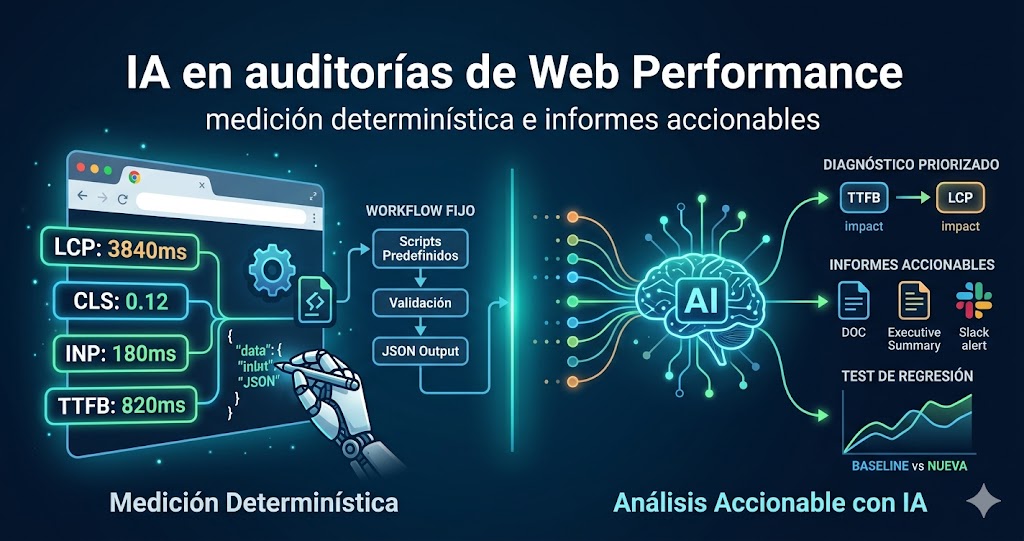
Una auditoría de web performance tiene dos fases con naturalezas muy distintas. La primera es recopilar datos: medir LCP, CLS, INP, TTFB, analizar recursos, detectar antipatrones. La segunda es interpretar esos datos: identificar qué problemas importan más, explicar el mecanismo detrás de cada uno y proponer soluciones priorizadas por impacto.
La IA ayuda en ambas fases, pero de formas completamente distintas. Confundirlas lleva a resultados poco fiables.
La medición no improvisa
El problema con dejar que un modelo de IA genere el código de medición en el momento es que nada garantiza que lo ejecute de la misma forma si lo solicitamos de nuevo. Los LLMs pueden interpretar, "optimizar" o adaptar el código según el contexto de la conversación. Para diagnóstico de rendimiento, eso no es aceptable: necesitamos que las mediciones sean consistentes entre sesiones, entre agentes y entre modelos.
El enfoque que aplicamos es diferente: el agente no genera JavaScript, lee scripts predefinidos, testados y validados, y los ejecuta directamente en el navegador vía Chrome DevTools MCP, siguiendo el modelo de los Agent SKILLs de WebPerf Snippets. El resultado de cada script es un objeto JSON estructurado, no texto de consola:
{
"metric": "LCP",
"value": 3840,
"rating": "needs-improvement",
"element": "IMG",
"url": "https://cdn.example.com/hero.jpg",
"renderTime": 3840,
"loadTime": 2100
}El agente sabe que rating: "needs-improvement" activa el workflow de LCP. Ese workflow indica que el siguiente paso es desglosar el tiempo en TTFB, load delay, load time y render delay. La lógica de decisión está en la SKILL, no en el modelo. Los scripts devuelven además retornos estructurados en lugar de texto formateado para humanos, lo que hace que el agente pueda procesarlos directamente sin parsear la consola.
Del dato al diagnóstico
Con las métricas recogidas de forma fiable, empieza el trabajo donde la IA sí aporta valor real: interpretar, conectar y priorizar.
El agente recibe, por ejemplo, estos resultados tras analizar una página de producto:
{
"LCP": { "value": 4200, "rating": "poor", "element": "IMG" },
"CLS": { "value": 0.08, "rating": "needs-improvement" },
"INP": { "value": 180, "rating": "good" },
"TTFB": { "value": 820, "rating": "poor" },
"render_blocking": ["fonts.googleapis.com/css2", "vendor.min.css"],
"preload_async_conflicts": 3
}A partir de aquí, la IA no está midiendo: está razonando. El TTFB elevado explica parte del LCP malo. Los recursos render-blocking añaden latencia antes de que empiece a pintar. Los conflictos preload + async generan presión de prioridad en recursos que no la merecen. El CLS elevado probablemente está relacionado con los recursos de fuentes bloqueantes.
Este tipo de análisis cruzado (donde un dato explica otro) es donde un agente bien contextualizado aporta valor real. Conecta información dispersa y genera un diagnóstico coherente que, de otra forma, requiere varias iteraciones manuales.
El flujo de auditoría completo
Con un agente conectado al navegador vía Chrome DevTools MCP, el flujo completo pasa de ser una serie de acciones manuales a un proceso estructurado:
1. Navegar a la URL
2. Medir Core Web Vitals → LCP, CLS, INP
3. Si LCP > umbral → desglosar en TTFB, load delay, load time, render delay
4. Si TTFB > umbral → desglosar en DNS, TCP, TLS y tiempo de servidor
5. Analizar recursos → render-blocking, conflictos preload+async
6. Recopilar todos los resultados estructurados
7. Generar informe con diagnóstico, priorización y soluciones concretas
8. Exportar en el formato necesario (documento técnico, resumen ejecutivo, alerta en Slack)
Los pasos 1 al 6 son determinísticos: el agente ejecuta scripts fijos y recoge datos fiables. Los pasos 7 y 8 son donde la IA genera contenido a partir de esos datos. La separación garantiza que el informe refleja lo que realmente hay en la página, no lo que el modelo cree que podría haber.
El formato de salida es donde el agente tiene más libertad. El mismo conjunto de métricas puede convertirse en un documento técnico para el equipo de ingeniería, un resumen ejecutivo para negocio, o una alerta automática cuando una métrica cruza un umbral.
Test de regresión: de la auditoría puntual a la monitorización continua
Una auditoría puntual captura el estado de una página en un momento dado. El valor real llega cuando esa auditoría se convierte en una línea base contra la que comparar cambios futuros.
El flujo de regresión parte del mismo conjunto de scripts determinísticos:
1. Auditoría inicial → guardar métricas como baseline
2. Tras cada despliegue → ejecutar los mismos scripts sobre el mismo entorno
3. Comparar nuevos valores con baseline
4. Si alguna métrica provoca una regresión → identificar qué cambió
5. Generar alerta con diagnóstico del cambio
El agente no se limita a detectar que el LCP empeoró de 2.1s a 3.8s. Cruza esa información con los cambios recientes y genera un diagnóstico concreto: "el LCP empeoró 1.7s tras introducir un recurso de fuente sin font-display: swap". Esto convierte la auditoría en una red de seguridad que actúa antes de que un problema llegue a producción.
La IA acelera; el criterio sigue siendo humano
El agente reemplaza las partes repetitivas y mecánicas que consumen tiempo sin añadir valor analítico. Navegar a ocho URLs distintas y ejecutar los mismos scripts en cada una es trabajo mecánico. Detectar que en cuatro de ellas hay conflictos preload + async y que todos vienen del mismo origen es trabajo analítico que el agente hace bien cuando tiene datos fiables.
Decidir si la solución es eliminar los preloads o añadir fetchpriority="low" según el rol de esos recursos en cada página, o evaluar si el banner de consentimiento debe priorizarse porque puede ser el elemento LCP de las primeras visitas, es trabajo que requiere conocimiento del producto. El mismo principio aplica al debugging de Long Tasks con Gemini y Chrome DevTools MCP: el agente conecta directamente al navegador y actúa sobre el código fuente real, pero la decisión de qué fix aplicar sigue siendo humana.
La IA acelera la recopilación de datos y la generación de informes. La interpretación de qué importa más en el contexto de cada producto sigue requiriendo conocimiento del dominio.
Conclusión
Separar la medición (determinística, basada en scripts) del análisis (contextual, generado por IA) es lo que hace que este enfoque funcione en la práctica. Los scripts garantizan que el agente mide lo mismo cada vez, de la misma forma, independientemente del modelo o la sesión. Los datos estructurados que producen son la entrada que permite razonar con precisión.
El test de regresión continuo es la extensión natural: una vez tienes un baseline fiable y scripts reproducibles, automatizar la comparación es el paso siguiente. El agente pasa de herramienta de auditoría puntual a sistema de alerta preventiva.
En Perf.reviews aplicamos este enfoque en nuestras auditorías y en el soporte continuo de rendimiento. Si quieres saber cómo puede mejorar el análisis de tu web, contáctanos.